

Increasing Reusability
Contents
There are many approaches to making software easier to reuse, but I will focus on only one of these that is particularly relevant to object-oriented programming: In software systems, it is common that certain modules, data structures, or other elements will be used over and over again, with minor modifications each time. The normal solution to this problem has been to simply copy and paste, and modify the copy to do the new task. This works if there are only a few changes to be made. But as the complexity of the changes grows, and as you start modifying a copy of a copy of a copy, bugs start creeping in faster than you can catch them.
A better way to reuse these programming modules is to keep the original module intact as a kind of template to refer to, and then define new modules by listing just the changes made from the original template. Then if a function or variable hasn’t been listed in the new module, you know that it’s exactly the same as in the original. This approach is called behavior sharing because other than the changes that have been explicitly listed, the new module shares the behavior (functionality) of the original one. Since all the identical code doesn’t have to be copied from the original, behavior sharing keeps code simpler and saves a lot of time.
Classification and Inheritance
In OOP, shared behavior is achieved by defining some kind of template of what a particular object looks like. In the {tooltip}vast majority of object-oriented systems{end-link}Prototyping is the other, less popular, means of achieving object-oriented behavior sharing. Basically, after an object is defined, another similar object will be defined by referring to the original one as a template, then listing the new object’s differences from the original. Act1 and DELEGATION are object-oriented programming languages that use prototyping for behavior sharing rather than classification. Hybrid and Exemplars use both methods. In prototyping systems, objects themselves are the templates, while classification systems use classes as templates for objects. The classification approach is so predominant in OOP that many people would define objects as encapsulations that share data by classification and inheritance. However, I have chosen to use the expression “behavior sharing”, as this includes the alternate technique of prototyping.{end-tooltip}, this is done by defining a template called a class (but see Okoli 1996). Every object created belongs to a class. Every object in a class has exactly the same kind of data members and methods, so once you know an object’s class you know exactly what the object is like.
Classes are hierarchical, which means that classes have superclasses and subclasses. Look at the following example from high school geometry:
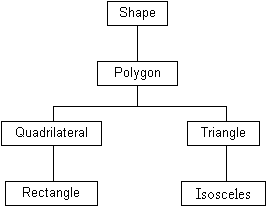
The Rectangle class is a subclass of the Quadrilateral class, which is a subclass of Polygon, which is a subclass of Shape. Going the other way, Shape is Polygon’s superclass, which is Quadrilateral’s superclass, which is Rectangle’s superclass.
In a class hierarchy, every class has a superclass except for the class at the top of the hierarchy; this called the root class. In our example, Shape is the root of the hierarchy. From the other end, the classes that don’t have any subclasses, like Rectangle and Isosceles are called leaf classes. (Funny names? Well, think of a class hierarchy as an upside-down tree; then you’ll get the picture.)
Notice that a single class can have more than one subclass, as does Polygon. This makes sense, since there are many kinds of polygons. In fact, other than triangles and quadrilaterals, there are also pentagons, hexagons, and many other shapes with multiple sides. But a class hierarchy for solving a programming problem doesn’t have to include every conceivable class, only those that will likely be necessary.
The OOP class system is a lot like the biological classification system for living things: If I tell you that a drill is a large, light brown animal with a short tail, you might have no idea what a drill looks like. If I tell you it’s a monkey, then you immediately get a picture in your mind, because you know what all monkeys generally look like; so you simply color your mental monkey light brown, make it large, and give it a short tail. You wouldn’t confuse a drill with a mastiff, a large, light brown, short-tailed dog, because a dog is a different kind of animal from a monkey. (To see how good your mental imaging is, compare this drill and mastiff with what you had in your mind.)
Similarly, if I tell you that I have an object called someShape in our shape hierarchy whose sides are 4 inches each, could you draw it? Not really, at least not until I further tell you that someShape is a heptagon. Then you know it’s a member of the Polygon class with seven sides of 4 inches each, and you know exactly what it looks like. (Note that you can create an object whose class is anywhere along the hierarchy; it doesn’t have to be a leaf class like Rectangle or Isosceles.)
It’s important to understand that {tooltip}an object is distinct from its class{end-link}In some OOPLs like Smalltalk and Java, classes are objects themselves. This feature gives some powerful programming flexibility, but even in this case a class is never its own class; rather, a special class is defined in these languages to classify classes. Does that make your head spin? I understand.{end-tooltip}. The class Rectangle describes what rectangle objects look like and what they do, but it’s not the same thing as a rectangle object. The programmer creates objects that are instances of a particular class. For example, you could create three objects of the Rectangle class called r1, r2 and r3. These are rectangle objects, but none of them represents the idea (class) “Rectangle”. In our biology example, a drill is an instance of a Monkey, but not all Monkeys are drills. In object-oriented jargon, creating an object that is an instance of a class is called instantiation.
The Shape Class Hierarchy
Classification makes it easy to reuse code in OOP. To demonstrate this with C++, let’s consider our shape hierarchy. Since a shape is so simple and we have no idea what a particular shape might look like (remember, a point or even a line is a shape), all we might want for now is for a shape to be able to create itself. So the only member that we give the class Shape is the method {tooltip}create(){end-link}In most OOPLs, including C++, a special kind of method called a constructor is used to create objects. However, I’ll keep things simple here by ignoring constructors. This introduction focuses on OOP concepts, not on OOPL syntax. The sample OO program, though, will use constructors and explain a little bit how they’re used.{end-tooltip}. (Note the open-and-close parentheses “()” that identify a method, distinguishing it from a data member.) Our simple implementation of create will simply print out “New Shape created.”
class Shape {
public:
void create(void) {
cout << "New Shape created.";
// "cout <<" in C++ means, print to console output
// "void" in C++ means that no data type is returned
}
}
When we create a Polygon (a closed shape whose sides are straight lines), we have a better idea what this shape would look like and what we would want to do with it. First and foremost, we define a Polygon as a Shape. This apparently trivial step automatically gives us the create() method without having to redefine it. Because a Polygon is a Shape, it inherits all of Shape’s members (in this case just one method). As we go further down the hierarchy, you’ll begin to appreciate better the power of inheritance. For now, let’s give Polygon a numSides data member, and for some more functionality we’ll give it print() and listProperties() methods.
class Polygon: public Shape { // Define Polygon as a subclass of Shape
public: // "public" is part of the C++ information hiding schema
int numSides = 0;
void print(void) {
// insert printing code here
}
void listProperties(void) {
cout << "Polygon: numSides = " << numSides;
}
}
Notice that we don’t redefine the create() method in Polygon; it automatically inherits it from Shape.
Next we create a Quadrilateral (a polygon with four sides). In a traditional programming language, we would probably cut and paste the Polygon code to take advantage of the members we’ve already created. But in OOP, we simply define a Quadrilateral as a Polygon, and voila, we automatically inherit all its members.
There is one slight problem, though. We want to enforce the rule that a Quadrilateral has four and only four sides. The simplest way to do this in OOP is to rewrite the create() function for our purposes.
class Quadrilateral: public Polygon {
public:
int sideA, sideB, sideC, sideD;
void create(void) { // overriding the create() in Shape
numSides = 4;
cout << "New Quadrilateral created. ";
}
void setSides( int a, int b, int c, int d ) {
sideA = a;
sideB = b;
sideC = c;
sideD = d;
}
}
When we rewrite the create() method, then whenever this method is called for a Quadrilateral, its own create() will be called rather than Shape’s. This is an important OOPL feature: if the implementation in a superclass of a method or even a data member doesn’t meet our needs, we can always override it in this way.
Quadrilateral adds its own special members: data members to represent its four sides, and the method setSides() to set them. Notice that Quadrilateral automatically inherits Polygon’s print() and listProperties() methods. As long as it doesn’t mention these methods, then they’re inherited without changes. Quadrilateral also inherits the numSides data member; that’s why it could assign it the value 4 in the create() method.
Now, what if a programmer creates a Quadrilateral object and wants to set numSides to 6? The way the class is defined, there’s no way to do that. While I won’t get into the details of how different OOPLs implement information hiding, I will note here that since a Quadrilateral conceptually will always have four sides, the designer of the class doesn’t even give the programmer the option to accidentally change that value. Thus the very chance of that bug is easily eliminated. This is one of the advantages of programming with encapsulated objects.
So far, our object-oriented design has only saved us a few lines of code, but when you write programs in the order of thousands of lines and more, object-oriented design can easily cut your code in half. Not only does this save time, but it also saves you the headache of slugging through all that complex code you have to debug, which translates to exponential time and effort savings.
Multiple Inheritance
In the Shape class hierarchy, we’ve seen single inheritance, where each class (except the root) has one and only one superclass, though a class can have multiple subclasses. Consider this alternative hierarchy:
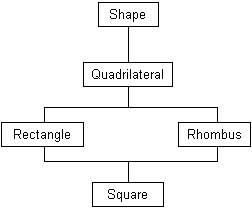
A Rectangle is defined as a Quadrilateral with four right (90°) angles, while a Rhombus is a Quadrilateral with four equal sides. A Square has four right angles and four equal sides, so it inherits the properties of both a Rectangle and a Rhombus. This is an example of multiple inheritance. C++ permits multiple inheritance in addition to single inheritance, and it gives a lot of flexibility in coding, as it more accurately models many real-world situations.
Multiple inheritance has one major drawback: when a class inherits members with the same name from two different classes, how do you figure out which one to use? Resolving this apparently simple problem can actually be such a nightmare that many OOPLs, like Smalltalk and Java, decide that it’s simply not worth the hassle (Gallagher 1990; Sutherland 1995; Wyant 1995).